
Table of Contents
As artificial intelligence continues to advance, the performance of large language models (LLMs) is becoming increasingly critical in evaluating their ability to understand and process complex tasks. The MMLU benchmark, alongside other benchmarks, plays a pivotal role in this evaluation process by offering standardized tests that provide a clear picture of an LLM’s capabilities. These benchmarks enable researchers and developers to assess how well models perform across a variety of domains, from reasoning and comprehension to decision-making and problem-solving.
What Are LLM Benchmarks?
LLM (Large Language Model) benchmarks are standardized tests designed to evaluate the performance of LLMs across various tasks and skills, such as reasoning, comprehension, and problem-solving. These benchmarks provide a structured way to assess how well an LLM handles specific tasks, enabling researchers and developers to measure improvements and track advancements in the field of AI.
An LLM benchmark typically consists of the following components:
- Tasks: A benchmark is made up of one or more tasks, with each task corresponding to its own evaluation dataset. These tasks are designed to test different aspects of an LLM’s performance, such as language comprehension, inference, or problem-solving. Each task has associated target labels (or expected outputs) that define the correct answer or response for the LLM to generate.
- Scorer: The scorer is used to determine whether the LLM’s predictions are correct. It compares the LLM’s output to the target labels provided in the dataset. Most benchmarks use an exact match scorer, where the model’s prediction is compared directly to the expected output, and a score is assigned based on the degree of correctness.
- Prompting Techniques: Benchmarks often use various prompting techniques to guide the model’s responses. These include techniques like few shot learning and Chain of Thought prompting.
In practice, the LLM will generate predictions for each task within a benchmark using the specified prompting techniques. The scorer then evaluates these predictions by comparing them to the target labels. While there is no universal scoring system across all benchmarks, most rely on exact match scoring, where the model’s output is compared directly to the target label.
What is the MMLU Benchmark?
MMLU or Massive Multitask Language Understanding is a rigorous benchmark designed to evaluate the multitask accuracy of language models in zero-shot and few-shot settings, making assessments both challenging and reflective of human evaluation methods. It covers a broad range of domains, from elementary math and history to advanced fields. The benchmark tests both general world knowledge and problem-solving abilities, with difficulty levels ranging from elementary to advanced professional. Its comprehensive scope and granularity provide a standardized way to measure model performance and effectively identify blind spots.
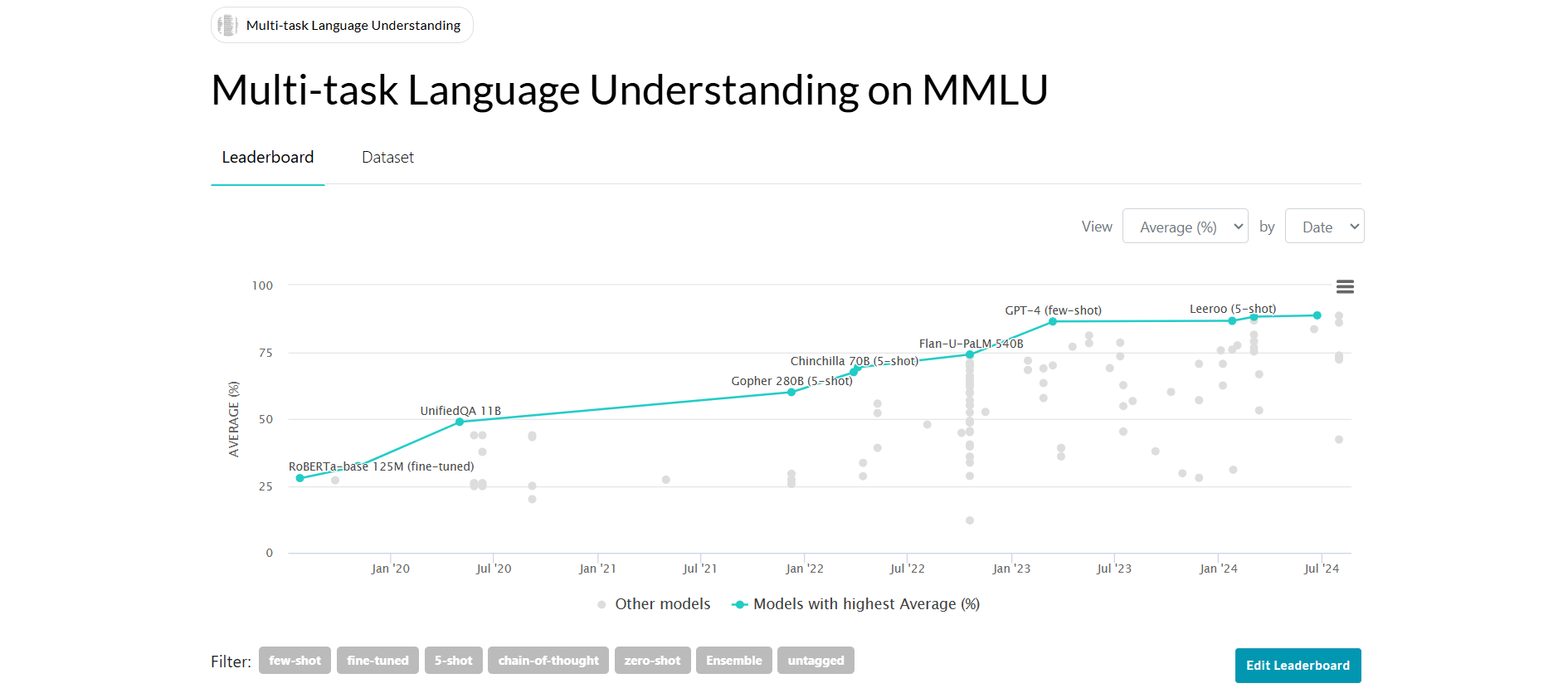
To really understand the significance of MMLU benchmarking let’s take a closer look at what zero shot and few shot means.
Zero-shot learning refers to the ability of a model to perform a task or make predictions on data it has never seen before, without requiring any task-specific training examples. The model relies on its general knowledge and contextual understanding to infer relationships or respond appropriately to the task. This capability demonstrates the model’s ability to generalize across tasks by leveraging the knowledge encoded during training. For instance, a language model trained broadly on diverse datasets can classify text, answer trivia, or interpret instructions in natural language for tasks it wasn’t explicitly trained for.
Few-shot learning is when a model learns to perform a task by being given only a small number of task-specific examples, typically provided as input-output pairs in the form of prompts. These examples help the model adapt its general knowledge to the specific requirements of the task, allowing it to generate appropriate responses or predictions based on new inputs without requiring extensive training on large datasets.
It provides a rigorous benchmarking framework that tests a model’s general knowledge, reasoning abilities, and adaptability without relying on additional training. Below are the key features that make MMLU an invaluable tool for assessing model performance:
Key Features of MMLU
- 57 Subjects: Covers a diverse range of topics, from elementary mathematics to advanced professional fields like legal reasoning, law, and ethics.
- Granularity and Breadth: Tests both world knowledge and problem-solving skills, offering a detailed evaluation of a model’s understanding across various domains.
- Multitask Accuracy: Assesses a model’s ability to perform well on a wide range of tasks without task-specific tuning.
- No Large Training Sets Required: Evaluates models based on knowledge acquired during pretraining, eliminating the need for additional task-specific training data.
Dataset
The dataset contains multitask test features multiple-choice questions across 57 subjects, including humanities, social sciences, hard sciences, and more. Covering areas like elementary math, US history, and law, it requires models to demonstrate extensive world knowledge and problem-solving skills.
But how does the MMLU Benchmark work?
The MMLU benchmark evaluates language models’ performance across different subjects, testing their ability to generalize knowledge and problem-solving skills.
- Zero-Shot and Few-Shot Evaluation: MMLU assesses models without extensive fine-tuning, mimicking real-world scenarios where models must perform with minimal context.
- Diverse Subject Coverage: It spans academic and professional fields, including STEM, humanities, and social sciences.
- Multiple-Choice Questions: Each subject includes a set of multiple-choice questions designed to test both general knowledge and reasoning skills.
- Scoring Methodology: The benchmark calculates a model’s performance by aggregating its scores across all subject areas and computing an average score as the final metric.
This comprehensive approach offers a clear and detailed measure of a model’s linguistic understanding and its ability to perform in multidisciplinary domains.
Benefits of the MMLU Benchmark
The MMLU benchmark provides significant advantages for evaluating language models.
- Quantitative Comparison: It delivers a robust, numerical framework to compare the performance of different language models systematically.
- Computational Efficiency: The benchmark is computationally lightweight and yields interpretable results quickly.
- Diverse Contextual Understanding: By testing a model’s ability to process and respond to varied linguistic and reasoning scenarios, MMLU captures essential aspects of versatility and comprehension.
These benefits make the MMLU benchmark an essential tool for researchers and developers, enabling precise evaluations and driving advancements in natural language processing and artificial intelligence.
MMLU-Pro: A New Standard for AI Benchmarks
MMLU-Pro is an enhanced version of the MMLU benchmark, designed to address the limitations of the original MMLU as AI models continue to advance. While MMLU has been pivotal in evaluating language models’ capabilities in tasks such as language comprehension and reasoning across various domains, its performance has plateaued, making it increasingly difficult to discern differences in model capabilities. To overcome this challenge, MMLU-Pro introduces several key improvements.
Improvements
- Emphasis on Complex Reasoning: MMLU-Pro extends the original benchmark’s knowledge-driven tasks by focusing on more challenging, reasoning-intensive questions. This shift better evaluates a model’s problem-solving and inference skills.
- Expanded Answer Choices: By increasing the number of answer options from 4 to 10, MMLU-Pro reduces the likelihood of correct guesses and raises the difficulty of the tasks, requiring more nuanced decision-making from models.
- Elimination of Trivial and Noisy Questions: MMLU-Pro removes overly simplistic or noisy questions that could distort results, resulting in a more accurate and reliable assessment of a model’s abilities.
- Improved Stability Across Prompts: MMLU-Pro demonstrates reduced sensitivity to prompt variations, lowering the variation in scores from 4-5% in the original MMLU to just 2%. This improvement ensures more consistent and comparable results across experiments.
- Chain of Thought (CoT) Reasoning Advantage: Models leveraging CoT reasoning perform significantly better on MMLU-Pro, underscoring its focus on complex reasoning tasks that benefit from a structured, step-by-step approach. This improvement contrasts with the original MMLU, where CoT reasoning offered no notable advantage.
Through these improvements, MMLU-Pro raises the bar for evaluating AI models by challenging them with more sophisticated tasks, a broader range of answer choices, and improved stability. With a more discriminative design, it provides researchers and developers with a tool that is better equipped to track advancements in the field, especially as models continue to improve and perform at higher levels.
Limitations
- Missing Contextual Information: Some questions lack critical context, making it difficult or impossible for models to provide accurate answers. These gaps, often caused by errors during data preparation, such as copy-paste mistakes, can lead to incomplete evaluations. This impacts model training by emphasizing the need for high-quality datasets and rigorous validation during the data preparation process. Incorporating additional quality checks or automated context verification tools could address this limitation.
- Ambiguous Answer Sets: Certain questions feature unclear or open-to-interpretation answer sets, which can confuse models and lead to inaccurate performance evaluation. This ambiguity not only hampers fair comparisons between models but also challenges researchers trying to interpret results meaningfully. To mitigate this, standardizing answer sets and providing detailed explanations for correct answers could improve clarity and reliability.
- Incorrect Answer Options: A small subset of questions contains outright incorrect answer options, which can skew results and misrepresent a model’s capabilities. This introduces noise into the evaluation process, making it harder to differentiate between true model errors and dataset flaws. Regular auditing of the dataset and leveraging crowd-sourced verification methods could help identify and eliminate such errors.
- Prompt Sensitivity: While MMLU-Pro has reduced prompt sensitivity compared to the original MMLU, some variation in results persists based on the specific prompts used. This variability complicates comparisons across different implementations and research studies. Addressing this issue could involve defining a set of standardized prompts or developing more robust evaluation protocols to minimize prompt-related discrepancies.
While MMLU-Pro raises the bar for evaluating language models with more sophisticated tasks, expanded answer choices, and enhanced stability, its limitations highlight the need for ongoing refinement. Issues like missing context and ambiguous or incorrect answer sets emphasize the importance of quality control in benchmark development. Despite these challenges, MMLU-Pro remains a valuable tool for tracking advancements in AI, offering insights into model performance on reasoning-driven tasks as the field continues to evolve.
Conclusion
Benchmarks like MMLU and MMLU-Pro are essential for evaluating and advancing AI models. MMLU offers a robust framework to assess general knowledge and reasoning across diverse domains, while MMLU-Pro introduces more complex tasks, expanded answer options, and improved stability to meet the demands of increasingly advanced models. Despite some limitations, such as contextual gaps and ambiguous questions, these benchmarks remain invaluable tools for tracking AI progress. They enable researchers and developers to refine models, address blind spots, and push the boundaries of what AI can achieve.
Related Reading:
- What is LLM in AI? Large Language Models Explained!
- StarCoder: LLM for Code — A Comprehensive Guide
- 10 Best Machine Learning Libraries (With Examples)
- How to Learn AI For Free: 2024 Guide From the AI Experts
- What is Cost Function in Machine Learning? – Explained
FAQs
What is the purpose of the MMLU benchmark?
The MMLU benchmark is designed to evaluate the performance of AI models in multi-task language understanding. It tests a model’s ability to handle a wide range of subjects and topics, simulating real-world scenarios where diverse knowledge and reasoning are required.
How does the MMLU benchmark assess AI models?
MMLU uses a dataset with questions covering over 50 domains, including humanities, sciences, and mathematics. These questions are structured to test factual recall, critical thinking, and advanced reasoning. By measuring the accuracy of model responses, MMLU highlights their strengths and areas needing improvement.
Why is the MMLU benchmark important for AI research?
The MMLU benchmark is crucial for evaluating the robustness and generalization of AI models. It provides researchers with insights into how well a model can apply knowledge across various fields, helping to refine algorithms and improve the real-world applicability of AI systems.