
Table of Contents
A Long Short-Term Memory (LSTM) network is a specialized type of Recurrent Neural Network (RNN) designed to handle sequential data. It was specially designed to overcome the limitations of traditional RNNs. While RNNs are designed to process and learn from sequential data, they often struggle with long-term dependencies due to the vanishing gradient problem. This issue arises when the gradients (used for updating the network during training) shrink to near zero or grow excessively large as information flows through multiple layers. As a result, RNNs find it difficult to capture and retain information from earlier in the sequence, leading to poor performance in tasks that require long-range memory. This is where LSTMs come in.
LSTMs are particularly effective at learning long-term dependencies between data points, allowing them to retain and use information from earlier time steps. This makes LSTMs ideal for processing tasks that require long-range memory, where the order and context of data are critical, such as time series prediction, natural language processing, and speech recognition. Their ability to maintain information over long sequences gives them a distinct advantage in tasks involving temporal data.
In this article, we will dive into what LSTMs are, how they function, and their role in handling sequential data effectively.
What is an LSTM?
Long Short-Term Memory (LSTM) networks are a powerful variant of Recurrent Neural Networks (RNNs) specifically designed to address a key challenge that traditional RNNs face: capturing long-term dependencies in sequential data. RNNs are capable of analyzing data with a temporal dimension—such as time series, speech, or text—by maintaining a hidden state that is passed from one time step to the next. However, RNNs often struggle with the vanishing gradient problem, which occurs during training when gradients (used to update model parameters) either become too small or grow excessively large. This issue prevents RNNs from learning long-term dependencies effectively, limiting their performance on tasks that require retaining information over extended periods.
LSTMs were introduced to solve this problem. By incorporating memory cells and gates into the network, LSTMs are able to regulate the flow of information, allowing the network to retain relevant data for much longer durations. This makes them especially useful for tasks where long-term context is crucial, such as time series forecasting, natural language processing (NLP), and speech recognition.
How do LSTMs Work?
LSTMs regulate the flow of information using three gates: the input gate, the forget gate, and the output gate. These gates control what information is stored, what is discarded, and what is used to influence future predictions, enabling the network to selectively retain long-term information while discarding irrelevant data.
Key Elements of an LSTM Cell:
- Input Gate: The input gate controls the flow of new information into the memory cell. It evaluates the current input and determines what should be added to the cell state, ensuring that important information is stored for future use.
- Forget Gate: The forget gate decides which information from previous steps should be discarded. This gate helps the LSTM network clear out outdated or irrelevant data, allowing it to focus on only the most pertinent information.
- Output Gate: The output gate filters the information in the memory cell and determines what will be passed to the next LSTM cell in the sequence. This ensures that only the most relevant context is forwarded to influence the future predictions.
Each of these gates uses a sigmoid activation function, which produces values between 0 and 1, enabling the network to either fully allow information to pass through or to partially retain it, based on its importance.
Structure of an LSTM Cell
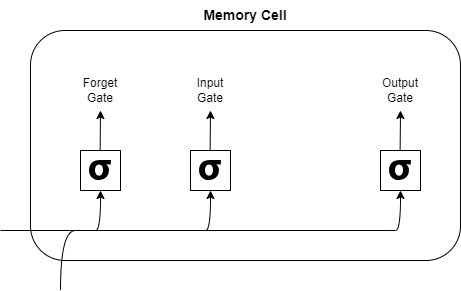
At the heart of the LSTM network is the memory cell, which maintains information over time. This memory cell is updated by the three gates mentioned earlier, ensuring that the LSTM network can retain long-term dependencies in sequential data. Each LSTM cell processes input data from the current time step and updates the cell state using the forget and input gates. Then, the updated cell state, along with the hidden state, is passed to the next LSTM cell in the sequence. This structure allows LSTMs to learn patterns over extended periods, making them highly effective for tasks involving long-term dependencies.
LSTM Network Architecture
LSTM networks are particularly suited for tasks that involve sequential data, such as classification, regression, and prediction tasks. Some key applications include:
- Time Series Prediction: LSTMs are commonly used for forecasting future values in time series data, such as stock prices or weather patterns, by learning from previous time steps.
- Speech Recognition: LSTMs excel at learning the temporal patterns in speech, which enables them to perform well in speech recognition systems by capturing the flow and rhythm of spoken words.
- Video Analysis: In video analysis, LSTMs can process sequences of images over time, capturing both motion and temporal changes. When combined with Convolutional Neural Networks (CNNs) for feature extraction, LSTMs can handle complex tasks such as video classification. CNNs first extract spatial features from individual frames, and LSTMs then model the temporal relationships between these frames.
Importance of Gates in LSTMs?
The gates in LSTMs play a fundamental role in how information is managed and processed over time. These gates act as filters, ensuring that only relevant information is retained and passed along, while irrelevant details are discarded. The following describes how each gate contributes to the effective functioning of LSTMs:
- Input Gate: Controls what new information enters the memory cell. It opens to allow important information in and closes when the input is not deemed useful for future steps.
- Forget Gate: Ensures that outdated or irrelevant information is discarded. It selectively “forgets” unimportant data, enabling the network to focus on more recent and relevant inputs.
- Output Gate: Determines which parts of the memory cell’s stored information should influence the next steps in the sequence. It decides what data should be output, based on its relevance to the current task.
This careful regulation of information allows LSTMs to manage long-term dependencies effectively, making them indispensable for applications that require both short- and long-term context.
Applications of LSTMs
Let’s explore some interesting use cases of LSTM networks.
Natural Language Processing (NLP):
LSTMs are widely used for NLP tasks such as language modeling, machine translation, and text summarization. By understanding the sequential structure of language, LSTMs can generate meaningful, contextually accurate sentences and improve translation accuracy between languages.
Speech Recognition:
In voice and speech recognition tasks, LSTMs are used to convert speech into text by identifying and processing patterns in audio sequences. Applications include speech-to-text transcription and command recognition, where LSTMs learn the relationships between spoken words and their corresponding text.
Sentiment Analysis:
LSTMs are effective for sentiment analysis, where they classify text as positive, negative, or neutral by learning the relationships between words and their emotional tone. This is commonly used in analyzing customer reviews, social media posts, and other textual content.
Want to build your own sentiment analysis tool?
Check out this comprehensive guide on how to build an AI based sentiment analysis tool.
Time Series Forecasting:
LSTMs excel at time series prediction by learning from past data points to predict future trends. They are used for tasks such as stock market forecasting, weather prediction, and sales forecasting, where long-term dependencies between time steps are essential.
Video Analysis:
In video analysis, LSTMs are employed to capture temporal relationships between frames, enabling them to understand and classify actions, objects, and scenes in videos. This is useful in applications like action recognition, object tracking, and video summarization.
Handwriting Recognition:
LSTMs can recognize and convert handwritten text into digital format by learning from sequential patterns in handwriting. This is particularly useful in applications like optical character recognition (OCR), where LSTMs analyze pen strokes and convert them to text.
Machine Translation:
LSTMs improve the accuracy of machine translation systems by capturing long-range dependencies between words and sentences. By processing both the source and target languages in a sequence, LSTMs ensure that translations are contextually and grammatically correct.
Anomaly Detection in IoT:
LSTMs are used for detecting anomalies in Internet of Things (IoT) devices by analyzing sensor data over time. In applications such as smart home security or industrial monitoring, LSTMs can identify unusual patterns or failures in equipment, providing timely alerts.
Autonomous Driving:
LSTMs play a role in autonomous driving by helping systems predict the future movements of vehicles, pedestrians, and other objects on the road. By processing sequential data from sensors and cameras, LSTMs aid in decision-making and navigation in dynamic environments.
Healthcare Predictive Modeling:
LSTMs are used in healthcare for predicting patient outcomes based on historical medical records. They can predict the likelihood of certain events, such as hospital readmissions, by learning from time-series data like vital signs, test results, and treatment history, improving patient care and decision-making.
Get started with this step by step guide on building an AI-based health diagnostic assistant that processes patients’ symptoms to predict the cause of illness.
These diverse applications showcase LSTMs’ ability to handle tasks that rely on learning from sequential data and capturing long-term dependencies, making them essential in a wide range of industries.
Comparison: LSTMs vs. RNNs
While both LSTMs and RNNs are designed to process sequential data by utilizing past information to influence current predictions, they differ significantly in how they handle long-term dependencies. Traditional RNNs use a simple hidden state mechanism, which tends to degrade as more information is processed, leading to difficulties in retaining long-range information.
LSTMs, on the other hand, solve this issue by introducing an internal state (or memory cell) that carries information across long sequences. In addition to the hidden state, LSTMs use their input, forget, and output gates to control the flow of information, allowing them to retain or discard information as needed. This architecture makes LSTMs far more effective for tasks where long-term context is critical, such as language modeling, sentiment analysis, and machine translation.
Bidirectional LSTMs (BiLSTMs)
Bidirectional Long Short-Term Memory networks (BiLSTMs) are an extension of traditional LSTMs that improve performance by processing input sequences in both directions—forward (from past to future) and backward (from future to past). This allows the model to gain a more comprehensive understanding of the entire sequence at each time step, as it has access to both preceding and following context. This bidirectional approach is particularly beneficial in tasks where understanding the full context is crucial, such as natural language processing (NLP), where the meaning of a word or phrase often depends on both its previous and subsequent words.
How do BiLSTMs Work?
A Bidirectional LSTM network consists of two layers of LSTMs:
- Forward LSTM: Processes the sequence from the start to the end (past to future).
- Backward LSTM: Processes the sequence in reverse, from the end to the start (future to past).
Both layers operate independently, and their outputs are combined at each time step, giving the network the ability to utilize information from both directions. This dual processing provides a richer context for the model to learn from, making it more effective in understanding the relationships between sequential data points.
Why are BiLSTMs Important?
The key advantage of BiLSTMs lies in their ability to capture both forward and backward dependencies in a sequence. In unidirectional LSTMs, the model only has access to past information when predicting the current output. While this can work well for many tasks, it often leads to incomplete context when the meaning of a data point depends on future information as well.
For example, consider these two sentences:
- “Server, can you bring me this dish?”
- “He crashed the server.”
In the first sentence, the word “server” refers to a waiter, while in the second sentence, “server” refers to a computer. The meaning of the word “server” changes based on the surrounding words. A unidirectional LSTM might struggle to determine the exact meaning of “server” because it only processes words from left to right, relying solely on preceding context. However, a BiLSTM processes the sentence in both directions, enabling the model to use the full context—both before and after the word—to accurately interpret its meaning. This ability to understand both past and future contexts makes BiLSTMs particularly effective for tasks where nuanced understanding of sequences is critical.
Conclusion
Long Short-Term Memory (LSTM) networks have revolutionized sequential data processing by overcoming the limitations of traditional Recurrent Neural Networks (RNNs). LSTMs effectively handle long-term dependencies, addressing the vanishing gradient problem that hinders RNNs in learning from long sequences. Their ability to retain and selectively filter information makes them ideal for tasks like time series prediction, natural language processing, and speech recognition.
By introducing memory cells and gates, LSTMs ensure that critical information is neither forgotten too soon nor unnecessarily retained, making them effective for tasks that require both short- and long-term context. Bidirectional LSTMs (BiLSTMs) further enhance performance by processing data in both directions, capturing richer contextual understanding.
From NLP and video analysis to healthcare and autonomous driving, LSTMs have become essential for a wide range of applications. Their capability to process complex sequential data makes them a cornerstone technology in AI and deep learning, offering powerful solutions for temporal data across industries.
Related Reading:
- How to Learn AI For Free: 2024 Guide From the AI Experts
- What is Cost Function in Machine Learning? – Explained
- How to Build a Sentiment Analysis Tool Using AI
- Best Generative AI Certifications and Courses Online
- 10 Best AI App Builders in 2024
FAQs
What is LSTM and why is it used?
LSTM (Long Short-Term Memory) is a type of recurrent neural network (RNN) architecture designed to address the issue of learning long-term dependencies in sequential data. It is used because traditional RNNs struggle with the “vanishing gradient problem,” making it hard to retain important information over long sequences. LSTMs, with their unique memory cells and gates, help in retaining and managing information across long time frames, making them ideal for tasks like time series prediction, speech recognition, and natural language processing.
What is the difference between RNN and LSTM?
The primary difference between RNN and LSTM lies in their ability to retain information over long sequences. Traditional RNNs suffer from the vanishing gradient problem, which makes them ineffective for learning long-term dependencies. In contrast, LSTMs overcome this issue by using memory cells and gates (forget, input, and output gates) that control the flow of information, allowing them to learn both short- and long-term dependencies more effectively. Essentially, LSTMs are a more advanced and robust form of RNN.
What are the 4 gates of LSTM?
LSTM networks actually have three main gates, but for clarity, they are often described alongside the cell state:
1. Forget Gate: Determines what information from the previous cell state should be discarded or kept.
2. Input Gate: Decides which new information will be added to the cell state.
3. Output Gate: Selects the information that will be output and sent to the next LSTM cell.
4. Cell State (Memory Cell): This represents the long-term memory of the network, holding information across time steps.
Together, these elements enable LSTMs to store, update, and output information efficiently over long sequences.
Why is LSTM used with CNN?
LSTMs are often combined with Convolutional Neural Networks (CNNs) for tasks that involve both spatial and temporal data, such as video analysis and activity recognition. While CNNs excel at processing spatial data (like images) by extracting features, LSTMs specialize in handling sequential data and temporal dependencies. When used together, CNNs can extract spatial features, and LSTMs can model the temporal sequence of those features, leading to more accurate predictions in tasks like video classification, image captioning, and action recognition.