
Table of Contents
NLTK Sentiment analysis is a popular Natural Language Processing (NLP) task that helps determine the tone or sentiment of a text. One of the most common Python libraries used for sentiment analysis is NLTK (Natural Language Toolkit), which provides various tools for processing and analyzing text data.
In this guide, we will explore the basics of sentiment analysis using NLTK, learn how to preprocess text, analyze sentiment, and interpret results.
What is NLTK Sentiment Analysis?
Sentiment analysis is used to determine the emotional tone or sentiment behind a body of text. It helps in understanding whether the sentiment expressed is positive, negative, or neutral. Sentiment analysis involves breaking down text into meaningful components and using machine learning models to assign sentiment scores.
For example, in customer feedback analysis we can categorize the following product/service reviews as positive, negative, or neutral:
- Positive sentiment: “I love this product!”
- Negative sentiment: “I hate this experience.”
- Neutral sentiment: “This is an average service.”
Popular tools for sentiment analysis include NLTK, TextBlob, and advanced machine learning libraries like BERT or GPT. Today, our focus will be sentiment analysis using NLTK.
Getting Started with NLTK
Before diving into sentiment analysis, make sure you have Python and NLTK installed. If you haven’t installed NLTK yet, you can do so by running:
pip install nltkOnce installed, open a Python environment (such as Jupyter Notebook) or any suitable IDE like VSCode and download the necessary resources for NLTK by running the following code:
import nltk
nltk.download('vader_lexicon')Understanding VADER for Sentiment Analysis
For sentiment analysis, NLTK uses VADER (Valence Aware Dictionary for Sentiment Reasoning), a pre-trained sentiment analysis model specifically designed for social media text. VADER is efficient at identifying polarity (positive, negative, neutral) and intensity (how strong or weak the sentiment is).
Steps to Perform Sentiment Analysis with NLTK
1. Importing Necessary Libraries
Start by importing the necessary modules, including NLTK and VADER:
from nltk.sentiment.vader import SentimentIntensityAnalyzer2. Initializing the VADER Analyzer
Next, create an instance of the VADER sentiment analyzer:
sentiment_analyzer = SentimentIntensityAnalyzer()3. Analyzing Sentiment of a Sample Text
You can now analyze the sentiment of any text by passing it to the polarity_scores() method:
score = sentiment_analyzer.polarity_scores(text)
print(score)The output will be a dictionary with four keys:
- Negative (
neg): The negative sentiment score. - Neutral (
neu): The neutral sentiment score. - Positive (
pos): The positive sentiment score. - Compound (
compound): The overall sentiment score (ranges from -1 to 1).
4. Interpreting the Sentiment Scores
The compound score is the most important metric:
- A score closer to 1 indicates a highly positive sentiment.
- A score closer to -1 suggests a highly negative sentiment.
- Scores around 0 are considered neutral.
Implementation
Let’s pass the a few example sentences to the method polarity_scores() and observe the results.
-
text = "Metaschool is a great resource for learning Web3!"
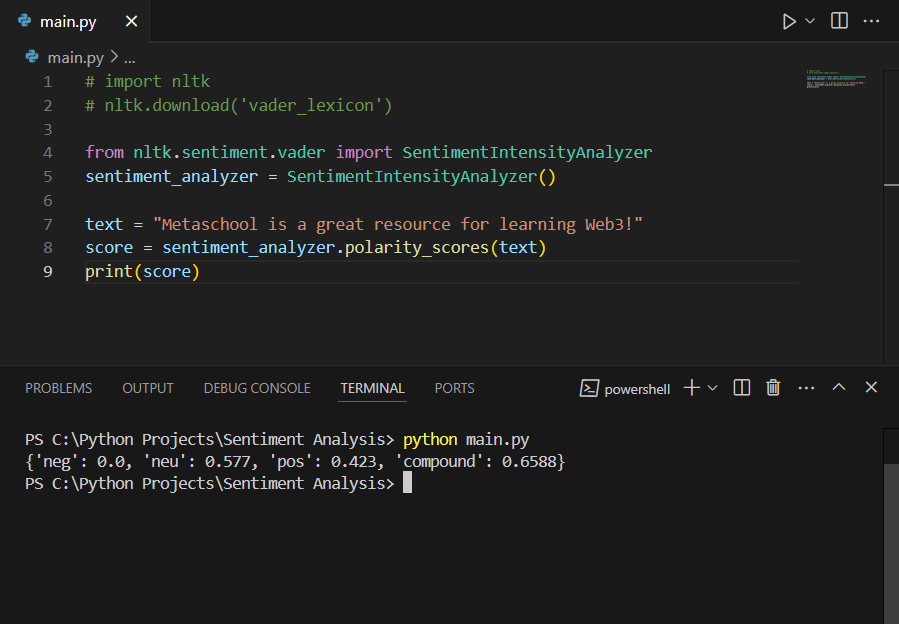
The compound score of 0.6588 shows that the given text had a positive sentiment.
text = "Sentiment Analysis is sooo hard to understand!"
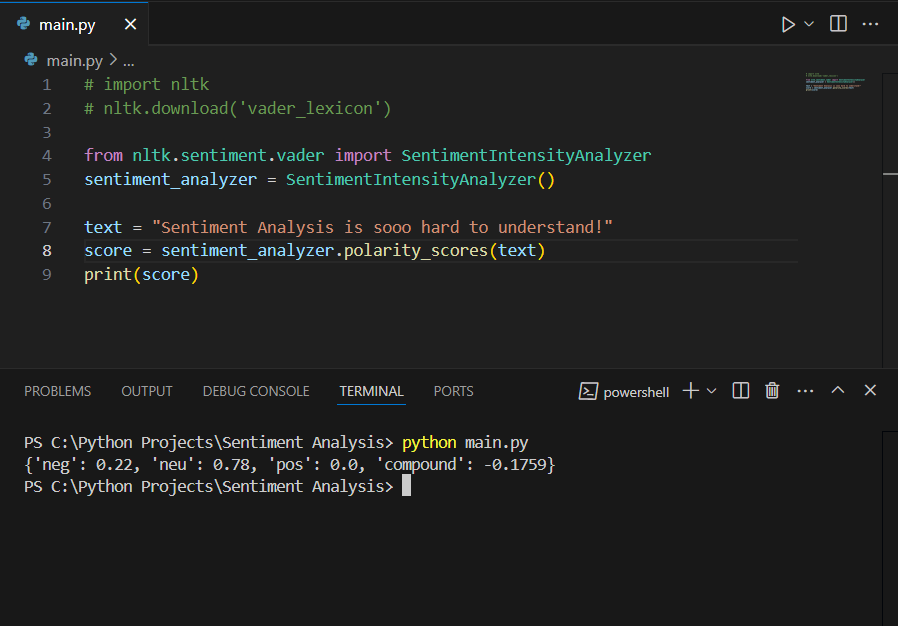
The compound score of -0.1759 shows that the given text had a negative sentiment.
text = "There ar 12 months in a year."
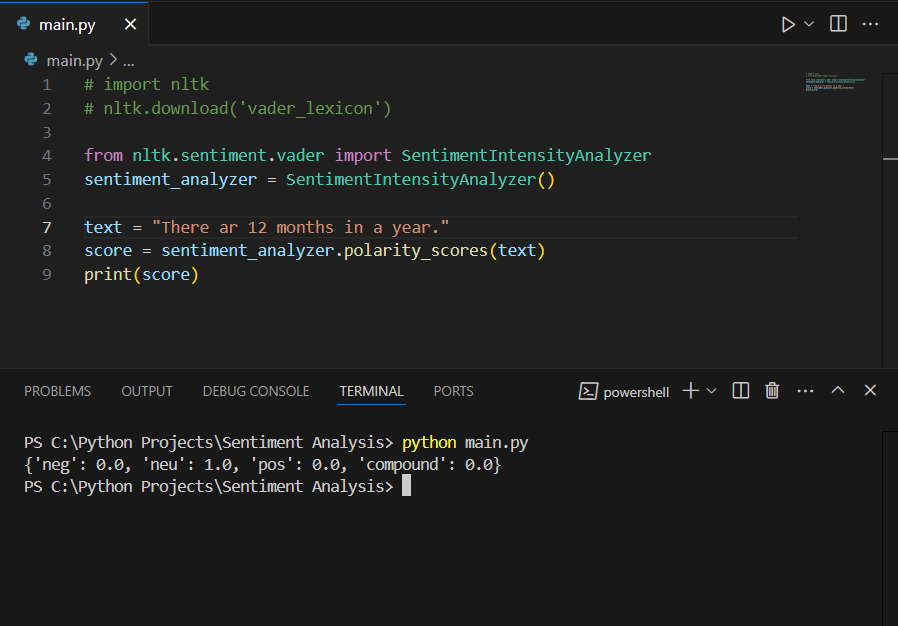
The compound score of 0.0 shows that the given text had a neutral sentiment.
Working with Real World Data
Real-world text data, unlike structured or cleaned data, is often messy and unstructured. So before applying sentiment analysis, it is a good idea to first preprocess the data to remove any irregularities.
Here are some problems that you may encounter in real-world data:
1. Misspellings and Grammatical Errors
Unlike neatly written datasets, real-world text (especially from social media) often contains misspellings, slang, and grammatical errors. For example, a user might write “luv” instead of “love” or “gr8” instead of “great.” This requires normalization during preprocessing to map variations to a standard form.
2. Abbreviations and Acronyms
Social media or SMS data often include abbreviations and acronyms (e.g., “LOL,” “OMG,” “IDK”) that may not carry their literal meaning and need to be interpreted correctly for sentiment.
3. Inconsistent Formatting
Real-world data lacks consistent punctuation and sentence structure, especially in platforms like Twitter, where users may use emojis, excessive exclamation points, or non-standard punctuation. Correctly identifying these patterns requires preprocessing.
4. Presence of Sarcasm and Irony
Sarcasm and irony make real-world text harder to analyze because the sentiment of the words often doesn’t align with the actual meaning. For instance, “Oh, great. Another rainy day!” appears positive but conveys negative sentiment.
5. Multilingual Text
It’s common for real-world text to include multiple languages, especially in global platforms. Handling multilingual text requires specific preprocessing steps, such as language detection and translation.
Data Preprocessing
Let’s discuss some corrective measures that you can apply to transform the data into structured text to ensure you get accurate results during sentiment analysis.
- Tokenization: Breaking the text into individual words or sentences.
- Lowercasing: Converting all text to lowercase to standardize it.
- Removing Stopwords: Eliminating common words (e.g., “the,” “and”) that do not contribute much to sentiment analysis.
- Removing Punctuation: Cleaning up punctuation marks.
Analyzing Sentiment for Larger Text Data
If you’re working with a dataset of reviews or tweets, you can loop through the text data and analyze the sentiment for each entry. Here’s an example using a list of sentences:
sentences = [
"The movie was fantastic!",
"I didn't like the plot.",
"It was an okay experience."
]
for sentence in sentences:
score = sentiment_analyzer.polarity_scores(sentence)
print(f"Sentence: {sentence}")
print(f"Sentiment Score: {score}")This allows you to quickly gather sentiment insights across multiple pieces of text.
Real-World Use Cases of Sentiment Analysis
- Social Media Monitoring: Businesses can track brand sentiment on platforms like Twitter or Facebook to understand customer opinions and identify areas for improvement.
- Customer Feedback Analysis: Sentiment analysis can be used to analyze product reviews, surveys, or support tickets to gain insights into customer satisfaction.
- Market Research: Companies can use sentiment analysis to gauge public opinion on new products, competitors, or market trends.
Tips for Effective Sentiment Analysis
- Context Matters: Sentiment analysis tools may struggle with sarcasm or nuanced opinions, so always interpret results with context in mind.
- Fine-Tune for Domain: Pre-trained models like VADER are generalized. For specific domains (e.g., financial text), you may need to fine-tune or use domain-specific lexicons.
- Combine with Other NLP Techniques: Sentiment analysis can be combined with other NLP tasks like topic modeling or named entity recognition (NER) for more comprehensive insights.
Conclusion
Sentiment analysis with NLTK is a powerful and easy-to-learn tool for extracting valuable insights from text data. With the VADER sentiment analyzer, you can quickly assess whether the tone of a text is positive, negative, or neutral. Whether you’re analyzing customer feedback, social media posts, or market research data, sentiment analysis can provide valuable insights into public opinion and emotional reactions.
If you’re interested in expanding your skills further, consider applying sentiment analysis techniques to chatbot development. Chatbots, like those powered by the OpenAI API, can benefit from sentiment understanding to improve interactions and offer more personalized responses.
For a hands-on guide to building a chatbot using OpenAI’s API, check out the Build a Yebot with OpenAI API course. It’s a great next step for anyone looking to dive deeper into AI-driven applications!
FAQs
How can sentiment analysis be improved for domain-specific text?
Pre-trained models like VADER are generalized and may not perform as well in specific domains like finance, healthcare, or legal texts. For better results, sentiment analysis can be improved by fine-tuning the model on domain-specific data or by creating a custom lexicon tailored to the specific language and jargon used in that field. For example, words like “volatile” or “bullish” might carry specific sentiment in financial contexts that wouldn’t apply in everyday language.
What are the ethical considerations in using sentiment analysis?
Sentiment analysis can raise ethical concerns, especially regarding privacy and consent. When analyzing personal communication, reviews, or social media posts, it’s important to ensure that the data being used is collected ethically and with consent. Additionally, sentiment analysis tools may introduce bias based on the training data, leading to skewed interpretations, especially when analyzing texts from different cultures or languages. Addressing these ethical concerns requires transparency in data collection and fairness in model design.
How does NLTK’s VADER tool work for sentiment analysis?
VADER is a pre-trained model in NLTK specifically designed for analyzing sentiment in social media and short texts. It assigns sentiment scores based on the intensity of words in the text. VADER uses four metrics: positive, negative, neutral, and compound scores, with the compound score indicating the overall sentiment of the text, ranging from -1 (most negative) to 1 (most positive).