
Table of Contents
The Allen Institute for AI (Ai2) has been at the forefront of advancing open-source AI models, especially their Tulu series that is fully open-source: the model, the data, code, tools used, evaluation methods, detailed training recipes (pretty much everything). This kind of openness allows researchers and developers to replicate, adapt, and build upon the model’s capabilities for various applications.
On 30th January, Ai2 introduced the latest addition to the Tulu family: the open-source billion-parameter large language model (LLM) Tulu 3 405. It even beats the top players like DeepSeek-V3 and GPT-4o in some critical benchmarks, and overall is neck and neck with the competition.
Building on the success of its predecessors, Tulu 3 represents a significant leap forward in terms of performance, scalability, and especially its accessibility. The first breakthrough of the Tulu 3 series was in 2024 when Ai2 released a model that uses a combination of advanced post-training techniques to get better performance. The possibilities of these post-training techniques were pushed even further with Tulu 3 405.
Although the DeepSeek-V3 model also uses post-training techniques, what sets Tulu 3 405 apart from its competition is the Reinforcement Learning from Verifiable Rewards or RLVR system. To better understand the significance of the Tulu 3’s success, let’s talk about how an RLVR system works.
What is the RLVR system?
According to Ai2, the RLVR system is the smarter way to train LLMs for tasks that have clear right or wrong answers. A model is given a prompt for which it generates a response which is then checked by a verifier function. If the output is correct, the model gets a reward ‘α’; if not, it gets nothing or ‘0’. It trains the model using, a reinforcement learning PPO algorithm, based on this reward system.
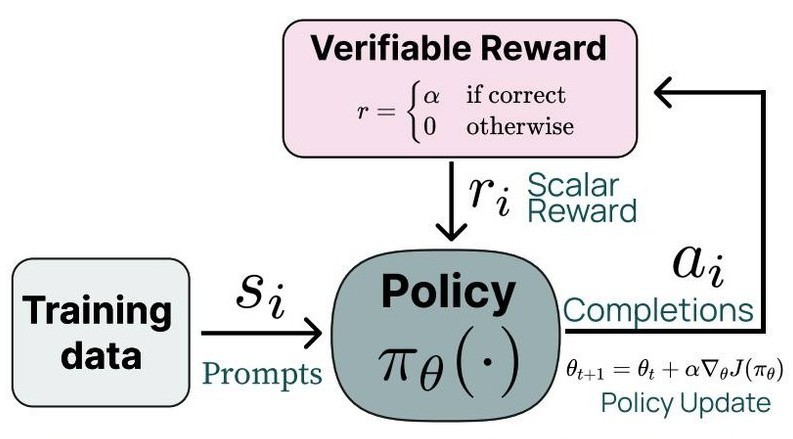
The greatest benefit of this method is the focused optimization of the model. Improving the task-specific precision of a model allows it to excel in domains where correctness or accuracy is the most important factor, like mathematical reasoning for example. But this task-specific precision also needs to be balanced out in some way to prevent the model from becoming too optimized for very very specific tasks. To do that, the RLVR system also utilizes SFT to ensure that the model still has general-purpose capabilities.
What is the Tulu 3 Recipe?
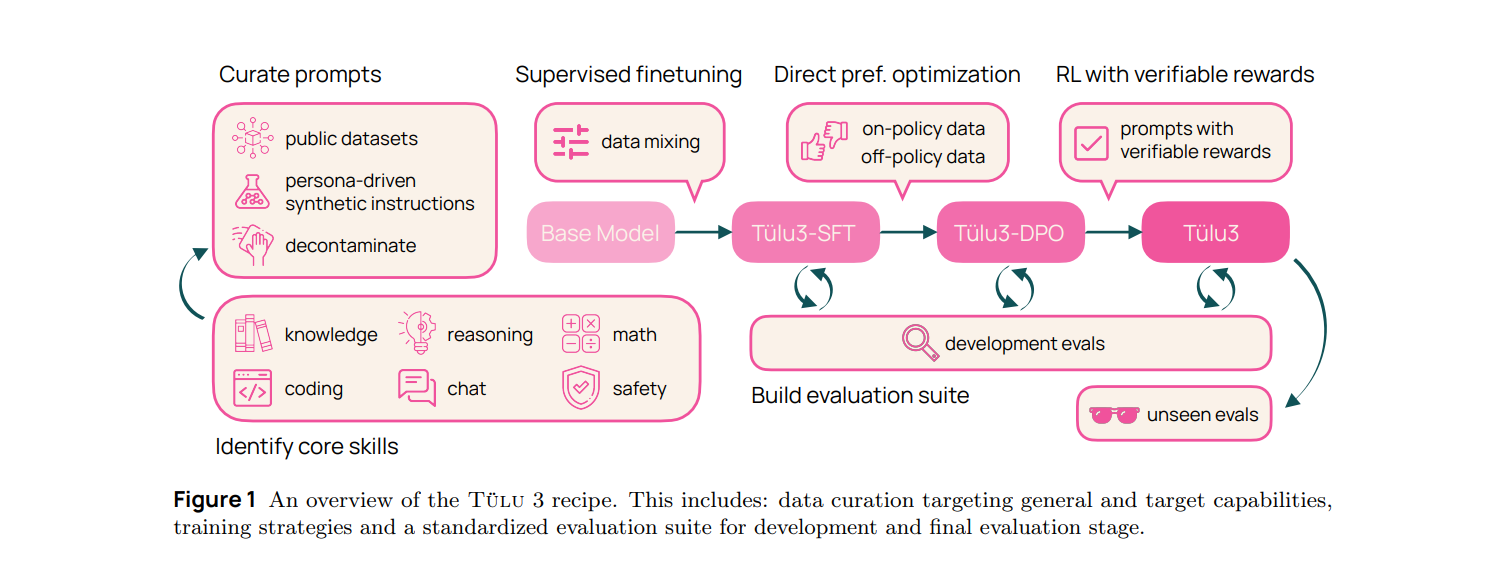
The Tulu 3 Recipe is basically a post-training pipeline that is designed to produce language models by building on top of other pre-trained language models. It incorporates advanced algorithmic techniques and a rigorous experimentation process to optimize data curation, training methods, and hyperparameters across different stages. The recipe is divided into four key stages, which are highlighted in the diagram below.
Let’s go over all the steps in detail.
In Stage 1, data curation is performed with great care. A diverse range of prompts is assembled from both synthetic sources and existing datasets to target core skills like reasoning, mathematical and coding knowledge, while also ensuring that these prompts remain uncontaminated by evaluation data. This stage essentially lays the foundation of the whole model by providing high-quality and purpose-driven input for the training process.
Stage 2 involves supervised fine-tuning (SFT). At this stage, the model is refined using carefully selected prompts and corresponding completions, with extensive experimentation to determine the optimal training data mix and hyperparameters. This fine-tuning process is critical for aligning the model’s performance with desired core skills without compromising its overall capabilities.
In Stage 3, preference tuning is applied. Techniques such as Direct Preference Optimization (DPO) are used to refine the model’s responses based on curated on-policy and off-policy preference data. By comparing model outputs in pairwise evaluations, the process identifies the best data formats and methods that lead to improved performance across various benchmarks.
Finally, Stage 4 employs the RLVR. Here, the model is further trained on tasks with measurable outcomes—like mathematical problem-solving—receiving constant rewards when its outputs are verified as correct. This stage is combined with a robust and asynchronous RL training infrastructure which significantly helps boost the model’s performance on complex reasoning tasks.
This was a very brief overview of the whole very complex that goes on behind the Tulu 3 405B model. If you want to learn more about how it works, check out this research paper that explains everything in great detail.
Tulu 3 versus DeepSeek-V3 and GPT-4o
Tülu 3, DeepSeek-V3, and GPT-4o are three of the most advanced LLMs that are available today, and each of them has its own unique strengths and weaknesses. Let’s briefly talk about each of them.
Tulu 3 is mainly recognized for its fully open-source approach and its elaborate training process. All the tools and techniques that are used to design this model are available for all to access and view which creates a sense of democracy in the AI community. Tulu is not only has a great performance on a range of benchmarks but its transparency also makes it highly reproducible and accessible for researchers and developers.
DeepSeek-V3 is noted for its impressive parameter count as well as its cost efficiency. DeepSeek-V3 performs well on a range of benchmarks (you can refer to the comparison table at the beginning) which allows it to excel in tasks like coding assistance, content creation, and general-purpose text generation. Its design prioritizes real-time efficiency and high-quality outputs, which makes it a good choice for applications where speed and accuracy are a priority.
GPT-4o still remains the top choice for the implementation of commercial AI solutions. This is especially due to its versatility which is why it was and is still being extensively used across diverse applications, from chatbots to enterprise-level natural language processing tasks. While GPT-4o is proprietary and benefits from OpenAI’s vast training data and continuous refinement, it often comes at a higher cost compared to its open-source alternatives aka Tulu 3 and DeepSeek-V3.
So if we look at it objectively:
- Tulu 3 stands out for its transparency and strong benchmark performance.
- DeepSeek-V3 impresses with its efficiency and cost-effectiveness.
- GPT-4o offers broad applicability and proven reliability in real-world scenarios.
Whichever model you decide to choose from these three depends a lot on the specific requirements of your use case, such as the need for open-source collaboration, budget constraints, or the desire for industry-leading versatility. I would recommend trying out all three and then deciding which fits your needs the most.
Looking Ahead
AI2 has set a new standard for open-source language models with the release of Tulu 3. Not only is the model advanced with top-notch performance, but its accessibility and ethical focus make it a very valuable resource for the AI community. As developers and researchers explore and utilize the potential of Tulu 3, we can expect to see a huge wave of innovative applications very soon.
In the words of Oren Etzioni, the CEO of AI2, “Tulu 3 is not just a model; it’s a platform for innovation. We’re excited to see how the community will use it to solve real-world problems and create new opportunities.“
Related Reading: