
Table of Contents
OpenAI developed the HumanEval benchmark dataset, which is designed to assess the ability and proficiency of large language models (LLMs) in code generation tasks. It provides a standardized framework that enables researchers and developers to evaluate how effectively AI models can understand and produce functional code, further advancing the field of AI-driven programming solutions.
Structure of the HumanEval Dataset
The HumanEval dataset is a collection of different problems designed to assess the code generation capabilities of large language models. Each problem in this dataset is structured to provide comprehensive information, ensuring that the model is evaluated on syntactical accuracy as well as functional correctness. Let’s look at the key components of each problem by using examples.
- Function Signature: This defines the function’s name, its parameters, and the expected return type. It serves as a blueprint, outlining the inputs the function will receive and the output it should produce. For example:
def add_numbers(a: int, b: int) -> int: Here, add_numbers is the function name, a and b are integer parameters, and the function is expected to return an integer.
- Docstring: A descriptive comment that explains the function’s purpose and behavior. It provides context and specifies the task the function is intended to accomplish, guiding the model in generating appropriate code. For instance:
"""
Adds two integers and returns the result.
""" This docstring states that the function should perform an addition operation on two integers.
- Function Body: The segment where the model is expected to generate code that fulfills the specified task. Based on the function signature and docstring, the model writes the implementation to achieve the desired functionality. For example:
def add_numbers(a: int, b: int) -> int:
return a + b In this case, the function body correctly adds the two input integers and returns the result.
- Unit Tests: A set of test cases designed to validate the correctness of the generated code. These tests provide specific inputs to the function and compare the output against expected results, ensuring that the implementation behaves as intended. For example:
def test_add_numbers():
assert add_numbers(2, 3) == 5
assert add_numbers(-1, 1) == 0
assert add_numbers(0, 0) == 0 These unit tests check various scenarios to confirm that the add_numbers function operates correctly across different cases.
This structure ensures that models are evaluated not just on code syntax but also on their ability to produce semantically correct and functional code solutions. By encompassing function signatures, descriptive docstrings, implementation bodies, and rigorous unit tests, the HumanEval dataset provides a robust framework for assessing the practical coding proficiency of language models.
Evaluation Metrics: Understanding pass@k
A vital tool for assessing code generation models, especially in benchmarks such as HumanEval, is the pass@k metric. It measures the probability that at least one of the top k code samples produced by a model for a particular problem will pass all related unit tests, indicating a proper solution.
For each problem, n samples are generated, and the number of correct samples is calculated. The probability that at least one correct sample will be included in the top k selections is then estimated by calculating the pass@k value through combinatorial methods. This approach gives a more accurate evaluation of a model’s performance by taking into consideration the potential for multiple correct answers.
Significance in Model Evaluation
Pass@k simulates real-world use, where users can examine multiple produced outputs to find the best or most accurate answer. A higher pass@k value increases the model’s usefulness by indicating a higher likelihood that users will locate the right answer among the top k recommendations.
Models are frequently ranked according to their pass@k scores in competitive settings. Commonly used metrics to compare how well models generate correct code in a given number of attempts include pass@1, pass@10, and pass@100.
The probability that the top (first) generated code sample is correct, for example, is indicated by pass@1. Greater pass@k values indicate a model’s improved ability to produce precise code in a constrained amount of tries. The HumanEval benchmark ranking of various LLMs is displayed in the graph below.
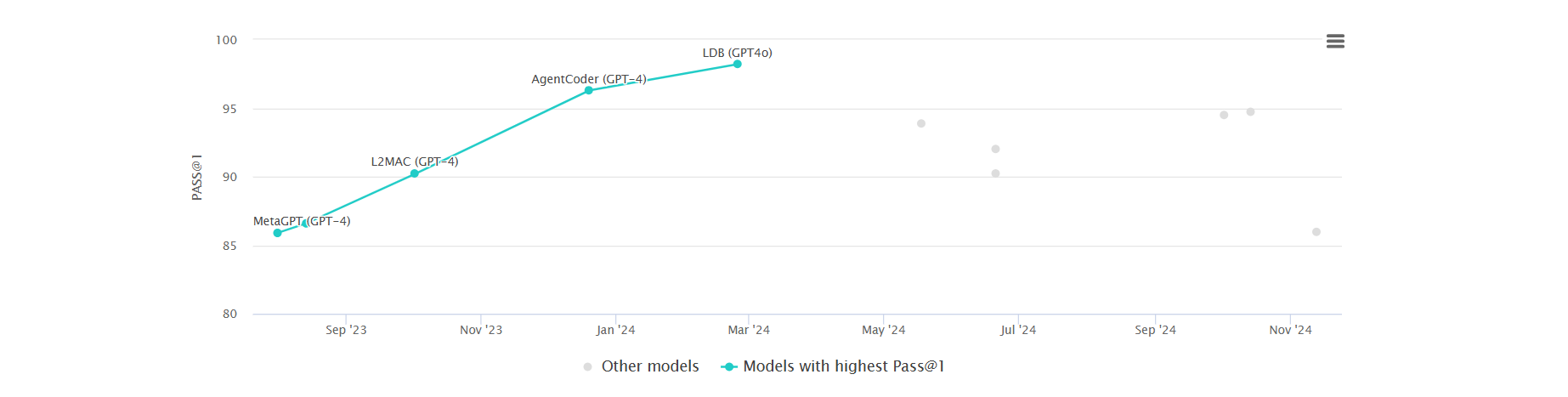
Key Considerations
It’s crucial to remember that the generated code samples might not be totally independent, particularly if the model uses comparable generation techniques for each sample. It is crucial to interpret the results in light of the model’s sampling techniques because this interdependence may have an impact on the pass@k metric.
Improving a model’s capacity to produce a variety of accurate solutions within the top k outputs is known as optimizing for higher pass@k values. Methods like enhancing sampling plans and adding more effective ranking systems can help achieve this objective.
Significance in AI Development
The HumanEval benchmark has become an important part of the development and refinement of Large Language Models (LLMs) for code generation. They offer several key contributions to the field:
- Standardization: HumanEval provides a consistent framework for evaluating and comparing the code generation capabilities of different models. By presenting a uniform set of programming challenges, it enables researchers and developers to objectively assess and benchmark model performance, facilitating meaningful comparisons across various LLMs.
- Functional Emphasis: Unlike benchmarks that focus solely on syntactical accuracy, HumanEval emphasizes on the generation of functionally correct code. Each problem includes unit tests that the generated code must pass; this ensures that the models are evaluated based on their ability to produce code that not only successfully compiles but also performs the intended task correctly.
- Advancing Research: HumanEval directs future research directions by pointing out the advantages and disadvantages of different models. It makes it possible to pinpoint particular areas in which models perform well or need to be improved, which helps to shape the creation of more resilient and powerful LLMs. The advancement of AI in code generation greatly benefits from this focused insight.
- Driving Innovation in AI Model Evaluation: Beyond evaluating individual models, benchmarks such as HumanEval are important because they support the larger AI community’s endeavors to create increasingly complex and powerful models. In order to make sure that models are assessed against pertinent and demanding standards, it is becoming more and more crucial to have up-to-date and thorough benchmarks as AI technology develops quickly.
The HumanEval benchmark has been instrumental in standardizing the evaluation of code generation models, emphasizing functional correctness, and guiding research to address current limitations.
Future Improvements for the HumanEval Benchmark
The HumanEval benchmark has been instrumental in assessing the code generation capabilities of large language models (LLMs). To maintain its relevance and effectiveness, several future directions are being considered:
- Multilingual Support: HumanEval would be more applicable and offer a more thorough assessment of LLMs’ adaptability if it were expanded to include more programming languages. This strategy is demonstrated by the MultiPL-E benchmark, which expands the scope of current Python-based benchmarks to include 18 other programming languages, making it easier to evaluate models across various programming paradigms.
- Integration of Complex Problems: Including more complex and varied programming tasks can provide a more thorough evaluation of a model’s performance. The PythonSaga benchmark, for example, overcomes the shortcomings of current datasets by including 185 manually created prompts that cover a balanced range of 38 programming concepts at different levels of difficulty.
- Real-World Application Testing: Analyzing models on tasks that replicate real-world situations can reveal information about their usefulness in practice. This is demonstrated by the RealHumanEval benchmark, which assesses LLMs’ capacity to help programmers with interactive coding tasks that mimic real-world programming assistance situations.
- Enhanced Evaluation Metrics: To properly evaluate LLMs’ performance, more exacting evaluation metrics must be created. By adding comprehensive test cases to current benchmarks, the EvalPlus framework makes it possible to assess the functional correctness of generated code in greater detail.
- Incorporation of Visual Context: Models’ capacity to comprehend and apply visual information can be assessed by incorporating visual components into coding tasks. The HumanEval-V benchmark uses code generation tasks with visual context to evaluate LLMs’ visual comprehension and reasoning skills.
By pursuing these enhancements, the HumanEval benchmark can continue to provide a robust framework for evaluating and advancing the code generation capabilities of large language models.
Conclusion
The HumanEval benchmark represents a significant stride in evaluating and enhancing the code generation capabilities of large language models. Its structured approach and emphasis on functional correctness have set a precedent for future benchmarks, driving the development of more sophisticated and versatile AI coding assistants.
Related Reading:
- What is the MMLU Benchmark — A Comprehensive Guide
- StarCoder: LLM for Code — A Comprehensive Guide
- Bert Model — A State of the Art NLP Model Explained
- What is Unsloth AI? Faster Open-Source LLM Fine-Tuning
Metaschool’s AI Comparison Tool
In the rapidly evolving landscape of artificial intelligence, selecting the appropriate model for your specific needs is crucial. Metaschool’s AI Model Comparison Tool is designed to facilitate this decision-making process by providing a comprehensive platform to evaluate and contrast leading AI models.
Key Features of Metaschool’s AI Model Comparison Tool:
- Comprehensive Model Database: Access detailed information on top AI models, including GPT-4, PaLM, Claude, and more. The tool offers insights into each model’s capabilities, architecture, and optimal use cases.
- Performance Metrics: Evaluate models based on critical parameters such as the Artificial Analysis Quality Index, output speed (tokens per second), and latency. For instance, models like ‘o1-mini’ and ‘Gemini 1.5 Pro (Sep ’24)’ have been assessed with quality scores of 82.0 and 80.0, respectively.
- Pricing Analysis: Compare the cost-effectiveness of models by examining pricing per million tokens. This feature enables users to balance performance requirements with budget constraints. For example, ‘Ministral 3B’ offers a competitive rate of $0.000 per 1M tokens.
- Integration Guides: Obtain practical guidance on integrating selected AI models into your applications, ensuring a seamless implementation process.
Benefits of Using the Tool:
- Informed Decision-Making: By presenting side-by-side comparisons, the tool empowers users to make choices that align with their specific needs and resources.
- Time Efficiency: Consolidating essential information into a single platform reduces the time and effort required to research and compare different AI models.
- Up-to-Date Information: Metaschool ensures that the data is current, reflecting the latest developments and releases in the AI field.
Whether you’re a developer, researcher, or business professional, Metaschool’s AI Model Comparison Tool serves as a valuable resource to navigate the complexities of AI model selection, enabling you to choose the most suitable model for your projects with confidence.
FAQs
What is the HumanEval test?
The HumanEval benchmark is a dataset developed by OpenAI to assess the code generation capabilities of large language models (LLMs). It comprises 164 hand-crafted programming problems, each accompanied by a function signature, docstring, body, and multiple unit tests, averaging 7.7 tests per problem. This setup evaluates a model’s ability to generate functionally correct code solutions.
What is a HumanEval dataset?
Is HumanEval only in Python?
What is pass 1 accuracy?
Pass@1 accuracy is a metric used to evaluate the performance of code generation models. It represents the probability that the top (first) generated code sample for a given problem passes all the associated unit tests, indicating a correct solution. A higher pass@1 accuracy signifies a model’s proficiency in producing correct code on the first attempt.