
Table of Contents
Large Language Models (LLMs), like ChatGPT or GPT-4, are AI systems designed to understand and generate human-like text. They power chatbots, translation tools, and content creators. At their core, LLMs are neural networks trained on vast amounts of text data to predict the next word in a sequence. Their magic lies in their ability to capture context, grammar, and even creativity—all thanks to a groundbreaking architecture called Transformers.
What are LLMs?
A large language model is designed to understand and generate human-like text. Built using transformer architecture — a type of neural network that processes language through self-attention mechanisms — LLMs can handle vast amounts of text data. Unlike traditional models that analyze input sequentially, LLMs process whole sequences in parallel, enabling faster training and the use of high-performance hardware like GPUs.
These models are trained on extensive datasets, often spanning billions of web pages, books, and other textual content. Through this training, LLMs learn the intricacies of language, grammar, and context, allowing them to perform a wide variety of tasks. These include generating text, translating languages, summarizing content, answering questions, and even assisting in creative and technical tasks like coding.
If you want to learn about the basics of LLMs in more detail, check out this comprehensive guide.
Architecture of a Transformer
Introduced in the 2017 paper Attention Is All You Need, the Transformer replaced older models (like RNNs and LSTMs) that struggled with long sentences and slow training. Transformers use attention mechanisms to process entire sequences of text at once, making them faster and more accurate. And most LLMs are built on the transformer architecture.
Let’s break down how they work!
Tokenization: Breaking Text into Pieces
Tokenization is the first step in preparing the input text for an LLM. It converts raw text, such as “Hello, world!”, into smaller units called tokens. These tokens can represent whole words (e.g., “Hello”), punctuation marks (“,” or “!”), subwords (parts of words), or even individual characters.
For example, a complex word like “unhappiness” might be split into subword tokens like “un” and “happiness”. This process simplifies how the model processes language, allowing it to handle rare or unfamiliar words by breaking them into recognizable chunks. Without tokenization, the model would struggle with variations in spelling, slang, or technical terms, making this step foundational to its ability to interpret diverse inputs.
Embeddings: Turning Words into Numbers
Once the text is tokenized, the model translates each token into a numerical representation called a word embedding. These embeddings are dense vectors (lists of numbers) that capture semantic meaning. For instance, words like “king” and “queen” might have similar vectors because they share contextual relationships (e.g., royalty). Similarly, words like “apple” and “juice” would have some similarity due to their frequent co-occurrence in sentences.
However, embeddings alone aren’t enough to fully understand language. While they capture the meaning of individual words, they don’t account for the order or structure of words in a sentence. For example, the sentences “The dog chased the cat” and “The cat chased the dog” use the same words but have entirely different meanings.
This is where positional encoding comes in. Positional encoding adds information about the position of each token in a sentence using mathematical patterns, often sine and cosine functions. For instance, the word “dog” in position 1 of a sentence gets a different positional vector than “dog” in position 5. This helps the model understand relationships like “Who let the dog out?” vs. “The dog chased the cat,” where the position of “dog” changes the meaning.
But even with embeddings and positional encoding, the model still needs a way to understand how words in a sentence relate to each other. This is where self-attention comes into play.
Self-Attention: The “Context Finder”
The heart of a Transformer is the self-attention mechanism, which determines how words in a sentence relate to one another. For every token, the model creates three vectors:
- Query (what the token is “looking for”)
- Key (what it “offers” to others)
- Value (the token’s core content)
The model then calculates attention scores between every pair of tokens by comparing their Queries and Keys. These scores decide how much “focus” each token receives from others.
For example, in the sentence “She drank apple juice,” the word “juice” might strongly attend to “apple” because their relationship is critical to the meaning. The attention scores are normalized using a softmax function, and the resulting weights are applied to the Value vectors. This creates a weighted sum that represents each token in the context of the entire sentence.
In simpler terms, self-attention allows the model to dynamically highlight relevant words. For instance, when thinking about “juice,” the model might emphasize “apple” because it’s the most relevant word in that context. This mechanism is what enables Transformers to understand complex relationships in text, making them far more powerful than older models that processed words one at a time without considering their connections.
Multi-Head Attention: Seeing from Multiple Angles
To capture diverse relationships, Transformers use multi-head attention. Instead of one set of Query/Key/Value vectors, the model creates multiple parallel “heads,” each with its own set of vectors. Each head learns to focus on different types of relationships—for example, one head might track grammatical structure, another could focus on semantic meaning, and a third might identify contextual nuances. The outputs from all heads are combined into a single representation, enriching the model’s understanding. This parallel processing allows the model to analyze sentences from multiple perspectives simultaneously, much like how humans consider tone, intent, and literal meaning when interpreting language.
Feed-Forward Networks: Processing the Insights
After attention, each token’s updated vector passes through a feed-forward neural network. This network applies non-linear transformations to the data, refining features and emphasizing certain patterns. For instance, it might amplify signals related to verbs in a sentence or dampen irrelevant details. Unlike attention, which mixes information across tokens, this step operates independently on each token’s vector. Think of it as a final “polishing” stage where the model digests the insights gathered from attention and prepares them for deeper layers or output generation.
Layer Stacking: Building Depth
Transformers stack multiple layers of attention and feed-forward blocks. Each layer refines the model’s understanding incrementally. In early layers, the model might learn basic grammar or word associations (e.g., “cat” and “dog” are both animals). Deeper layers handle abstract concepts, like irony or logical reasoning. For example, in the sentence “The movie was so bad it was good,” lower layers might parse the literal meaning, while higher layers recognize the sarcasm. This hierarchical processing mimics how humans analyze text—first grasping structure, then nuance.
Decoder (for Text Generation)
In models like GPT, the decoder generates text autoregressively, predicting one token at a time. It uses masked self-attention, which prevents the model from “peeking” at future tokens during training. For instance, when predicting the word “juice” in “She drank apple ___,” the decoder only attends to “She,” “drank,” and “apple”—not the blank position. This masking ensures the model learns to rely on context from earlier tokens.
During inference, the decoder iterates: it takes the user’s input, generates a token, appends it to the input, and repeats until a complete response is formed. Techniques like temperature scaling or top-k sampling add randomness to avoid repetitive outputs, balancing creativity and coherence.
Overview
This figure shows the Transformer architecture for sequence-to-sequence tasks.
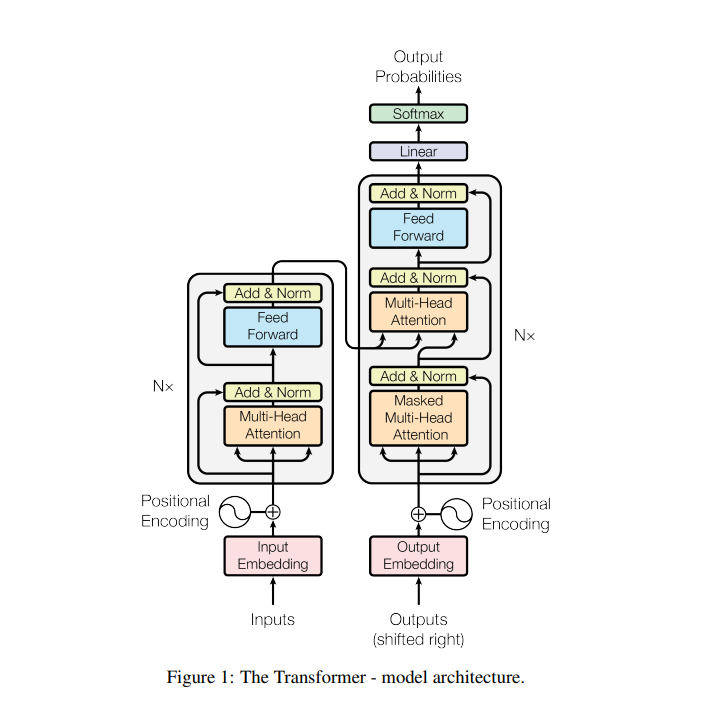
On the left is the encoder, which processes input embeddings (with positional encodings) through stacked layers of multi-head self-attention and feed-forward networks, each followed by Add & Norm steps.
On the right is the decoder, which similarly uses masked multi-head self-attention to handle the partially generated sequence, then attends to the encoder’s output, and finally applies a feed-forward network. The final linear layer and softmax produce output probabilities at each time step.
This design removes recurrence, enabling parallel processing while leveraging attention to capture dependencies across positions.
Training an LLM
Training a Large Language Model is a two-phase process: pre-training and fine-tuning. During pre-training, the model learns general language patterns by analyzing vast amounts of text data, often sourced from books, websites, and other publicly available content. This phase involves tasks like predicting the next word in a sentence or filling in masked (hidden) words.
For example, given the sentence “The cat sat on the ___,” the model might predict “mat” or “floor.” The model adjusts its internal parameters (weights) using a loss function, typically cross-entropy loss, which quantifies the difference between its predictions and the actual text. Over time, this iterative process helps the model grasp grammar, facts, and reasoning skills.
After pre-training, the model undergoes fine-tuning, where it is trained on smaller, task-specific datasets (e.g., question-answering pairs or conversational data) to specialize its knowledge. This step refines its behavior, ensuring it can follow instructions, avoid harmful outputs, or adapt to niche domains like medical or legal text. The combination of broad pre-training and targeted fine-tuning allows LLMs to balance versatility with precision.
Generating Text: How LLMs “Think”
When generating text, LLMs work autoregressively, meaning they produce one token at a time, using each new token as input for the next step. For instance, if a user asks, “What’s the weather like today?” the model might start with “Today’s,” predict “weather,” then append “is,” and so on, until it forms a complete response.
To balance creativity and coherence, models use sampling strategies. Greedy sampling selects the most probable token at each step, but this can lead to repetitive or rigid outputs. To introduce variety, temperature scaling adjusts the randomness of predictions—lower values make the model conservative (e.g., “sunny”), while higher values encourage riskier choices (e.g., “partly cloudy with a chance of rainbows”).
Top-k and top-p sampling restrict choices to the k most likely tokens or a cumulative probability threshold (p), respectively. For example, top-k=5 might limit the model to selecting from words like “sunny,” “rainy,” “cloudy,” “windy,” or “stormy” for weather-related contexts. These techniques ensure the output is both relevant and engaging, mimicking human-like variability without sacrificing logic.
Challenges and Considerations
Despite their capabilities, LLMs face significant challenges.
Computational cost is a major barrier—training a model like GPT-3 requires thousands of specialized processors (GPUs/TPUs) and millions of dollars, making it inaccessible to most organizations. Energy consumption and environmental impact are growing concerns too.
Bias and safety issues arise because models learn from human-generated data, which often contains stereotypes, misinformation, or toxic language. For example, a model might associate certain professions with specific genders due to biased training data. Ensuring outputs are safe and unbiased requires careful filtering and ethical guidelines.
Ethical dilemmas also loom large: LLMs can generate convincing fake news, plagiarize content, or replace jobs in writing and customer service. Addressing these challenges involves technical solutions (e.g., bias mitigation algorithms), policy frameworks (e.g., content moderation), and public awareness to balance innovation with responsibility.
Conclusion: The Power and Promise of LLMs
Large Language Models represent a monumental leap in artificial intelligence, combining the Transformer architecture’s ingenuity with vast computational resources to mimic human language understanding and creativity. At their core, LLMs like GPT-4 rely on tokenization to break text into manageable pieces, embeddings to capture meaning, self-attention to analyze context, and multi-head attention to explore diverse relationships. Layer stacking and feed-forward networks refine these insights, while the decoder generates coherent, context-aware text through autoregressive processes.
Training LLMs involves two phases: pre-training on massive datasets to learn general language patterns, and fine-tuning to specialize for tasks like answering questions or writing code. Despite their capabilities, challenges like computational costs, bias, and ethical risks underscore the need for responsible development.
Ultimately, LLMs are not just tools for generating text—they are gateways to democratizing access to knowledge, creativity, and problem-solving. As these models evolve, balancing innovation with ethical safeguards will be key to unlocking their full potential while ensuring they benefit society as a whole.
Related Reading: